

历久以来,开源多模态模子在复杂推理任务上,恒久与 GPT-4o、Gemini 等顶尖闭源模子存在沿途难以逾越的界限。
社区建筑者们逐步意志到,核肉痛点大致不在于模子架构的精进或者模子参数的领域。真确的瓶颈,在于高质地、想维链(CoT)密集的推理数据非常匮乏。
在纯文身手域,DeepSeek-R1 的到手已考据了高质地后测验数据(Post-training Data)的威力,但在多模态领域,咱们面临的是横亘在目下的「两座大山」:
数据失衡:现存开源多模态数据仍以浅薄 VQA 与当然图像为主,而关于真确具有高推理价值的数据,如 STEM 图表、逻辑谜题、复杂视觉象征等数据不仅少,何况标注资本极高。
推理质地交集不都:即便现存的「推理数据」也存在推理过程短、模版化,标注粒度不及、短少中间考据、视觉与逻辑推理割裂的问题。
为了填补这一空缺,上海 AI 实验室 OpenDataLab 盘问团队安逸开源了 MMFineReason 框架。这既是一套全历程 100% 基于开源生态、可复现的多模态推理数据合成 Pipeline,同期也开源了由此体式构建的包含 1.8M 高质地样本、5.1B Token 的大领域数据集。

论文标题:MMFineReason: Closing the Multimodal Reasoning Gap via Open Data-Centric Methods
Huggingface 论文:https://huggingface.co/papers/2601.21821
样貌主页:https://mmfinereason.github.io/
数据集 & 模子:https://huggingface.co/collections/OpenDataArena/mmfinereason
小模子,大性能:高效数据遴荐的远大上风
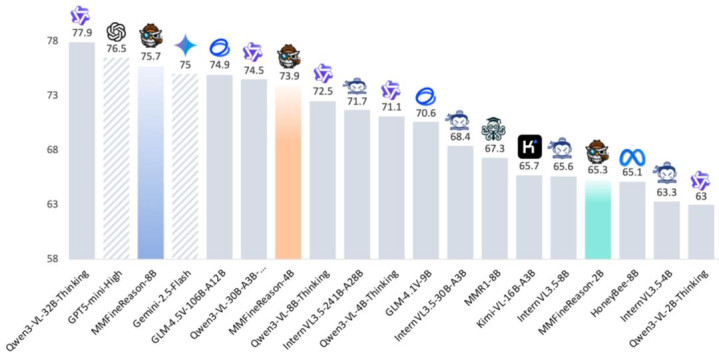
{jz:field.toptypename/}先来秀一秀性能遗弃。团队很惊喜的发现,MMFineReason 的出现,象征着多模态模子干预了「以小博大」的新阶段。
实验数据裸露,MMFineReason-4B 模子基于 Qwen3-VL-4B 测验而成,其推理材干不仅杰出了 Qwen3-VL-8B-Thinking,性能更是直逼 30B 参数领域的 Qwen3-VL-30B-A3B-Thinking。
更令盘问团队惊喜的是,相通基于同尺寸底座测验的 MMFineReason-8B,发达愈加优秀:它平直打败了 Qwen3-VL-30B-A3B-Thinking 和 Gemini-2.5-Flash,并运行向 GPT5-mini-High 及 Qwen3-VL-32B-Thinking 等顶级模子发起冲击。
值得强调的是,这种「跨级碾压」的性能跃迁并非来悔改的模子结构策画,也不是通过更复杂的测验手段兑现的,而险些完全源于数据层面的变化 —— 尤其是推理数据的结构化进程与单元样本中的有用推理密度。
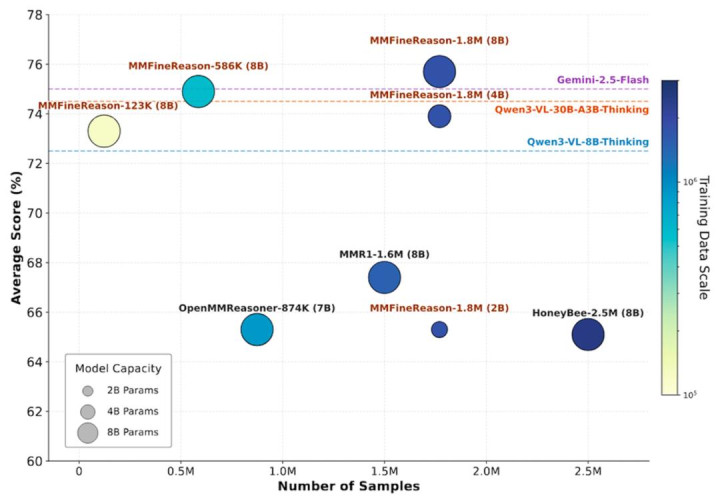
更进一步,团队还发现通过难度感知过滤,能兑现极高的数据调度后果:仅使用总量 7%(约 123K)的高难度精选子集数据,即可忘形全量 1.8M 数据相等的性能发达。
因此,当数据被有用筛选、难度与模子材干精准对都时,数据遴荐自身就成为决定参数后果的中枢杠杆。
揭秘「Closed-Source Level」数据管线:完全开源的数据坐褥线
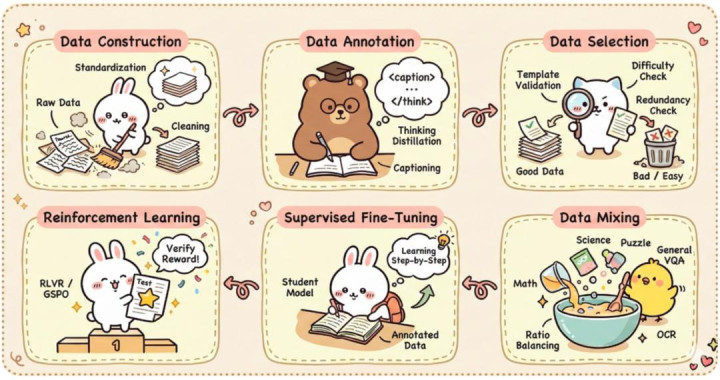
不同于依赖黑盒 API 的传统决策,MMFineReason 构建了一套完全开源的透明且高效的 Pipeline,全历程 100% 基于开源模子。扫数历程主要通过三个阶段来兑现高质地数据的坐褥:
数据圭臬化:最初从起源界说「什么是可推理任务」,对 STEM、Puzzle、图、几何、科学表等多领域数据进行圭臬化处罚并融合 Schema,并进行严格的清洗。
推理蒸馏:哄骗 Qwen3-VL-235B-Thinking 动作诚恳模子进行推理蒸馏,并严格战胜四阶段推理框架:「视觉感知 → 逻辑推导 → 中间考据 → 论断阐发」,从而来生成可贵且具备「视觉落地」材干的 CoT 推理轨迹。
双重过滤:为了确保测验的高效性,kaiyun sports团队引入了双层筛选机制,第一是正确性过滤,确保谜底与推理过程严格一致;在剔除低质地 CoT 的基础上,进行难度感知(Difficulty-Aware)过滤,异常筛选出对 Qwen3-VL-4B 小模子具有高「测验价值」的样本,即「小模子巩固失败」的样本,从而幸免了无效数据的堆砌。
最终,盘问团队赢得了 MMFineReason-1.8M(正确全量), MMFineReason-586K(正确且去掉过于浅薄样本),以及 MMFineReason-123K(正确且最贫瘠样本)三个高质地数据集。
MMFineReason-1.8M:专为「深度推理」打造的高质地多模态数据
与其说 MMFineReason 是一个老例的 VQA 数据集,倒不如将其界说为一个专为多模态大模子准备的「硬核想维测验场」。在现时多模态领域大宗堕入「数据饥渴」与「想维链断层」的配景下,该样貌展现出了极具辨识度的中枢特征。
最初,MMFineReason 在想维深度上兑现了质的飞跃。比拟 HoneyBee 等同类数据集,其平均想维链(CoT)长度达到了惊东说念主的 2,910 tokens,领域足足是前者的 2.7 倍。这种长旅途推理数据的引入,试验上是让模子告别了浅薄的「直观判断」,转而掌持一套详备且具象的「视觉 - 逻辑」推导范式。
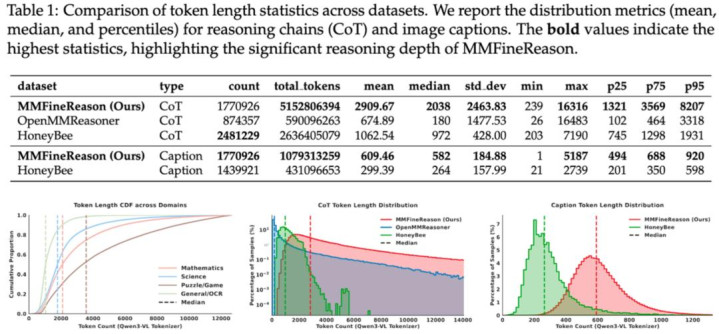
在领域溜达上,盘问团队展现出了昭着的去等闲化导向,坚韧拒却易于「刷分」的浅薄样本,转而深耕高难度逻辑本地。
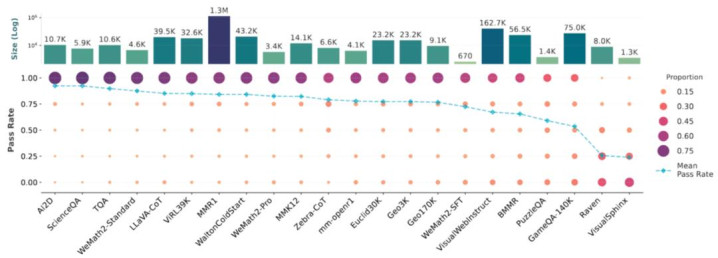
数据议论,数学领域以 79.4% 的全都占比强化了象征推理根基,涵盖了几何、微积分等深度学科;13.8% 的科学数据则聚焦于复杂的物理、化学图表分析;此外,数据集还引入了 4.6% 的谜题与游戏数据,通过轮廓步地识别与政策博弈,陆续试探并挑战开源模子的身手上限。
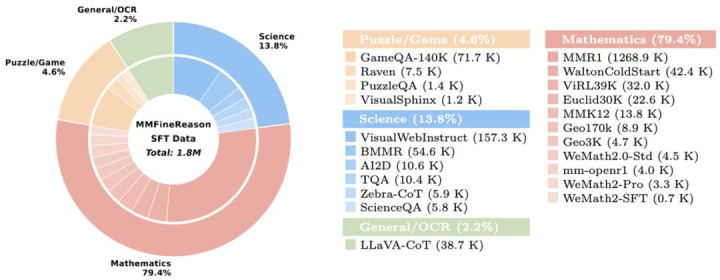
图为 MMFineReason 数据集的数据溜达情况。不错看到数据集的领域掩饰了数学、谜题与游戏、几何 / 微积分、图表与复杂科学等。
更具真切酷好的细察在于这种高强度测验带来的「协同普及效应」。实验遗弃突破了专项测验会减轻通用材干的固有剖判:当模子在 STEM 和逻辑难题上进行深度钻研时,其在一般性 VQA 任务上的发达反而赢得了同步增强。这种以点带面的材干开释,再次印证了高质地逻辑链条才是驱动模子性能跨级演进的真逻辑。
结语与意想
MMFineReason 的开源,讲解了在多模态领域,当模子架构逐步陆续、参数领域的边缘收益陆续着落,决定材干差距的,不再是模子有多大,而是「数据是否确凿教授模子怎样推理」。通过素雅化的数据工程,小参数模子完全有后劲在复杂推理任务上抵抗甚而杰出大参数模子。
这不是一次领域的到手,而是 Data-Centric 体式论的到手。咱们期待将来在多模态开源大模子的路上,能用更高效、更高价值的数据来促进社区的越过。
当今,该样貌已在 Huggingface 及 GitHub 全面上线,为开源社区提供了从数据到用具链的完好撑持。
 备案号:
备案号: